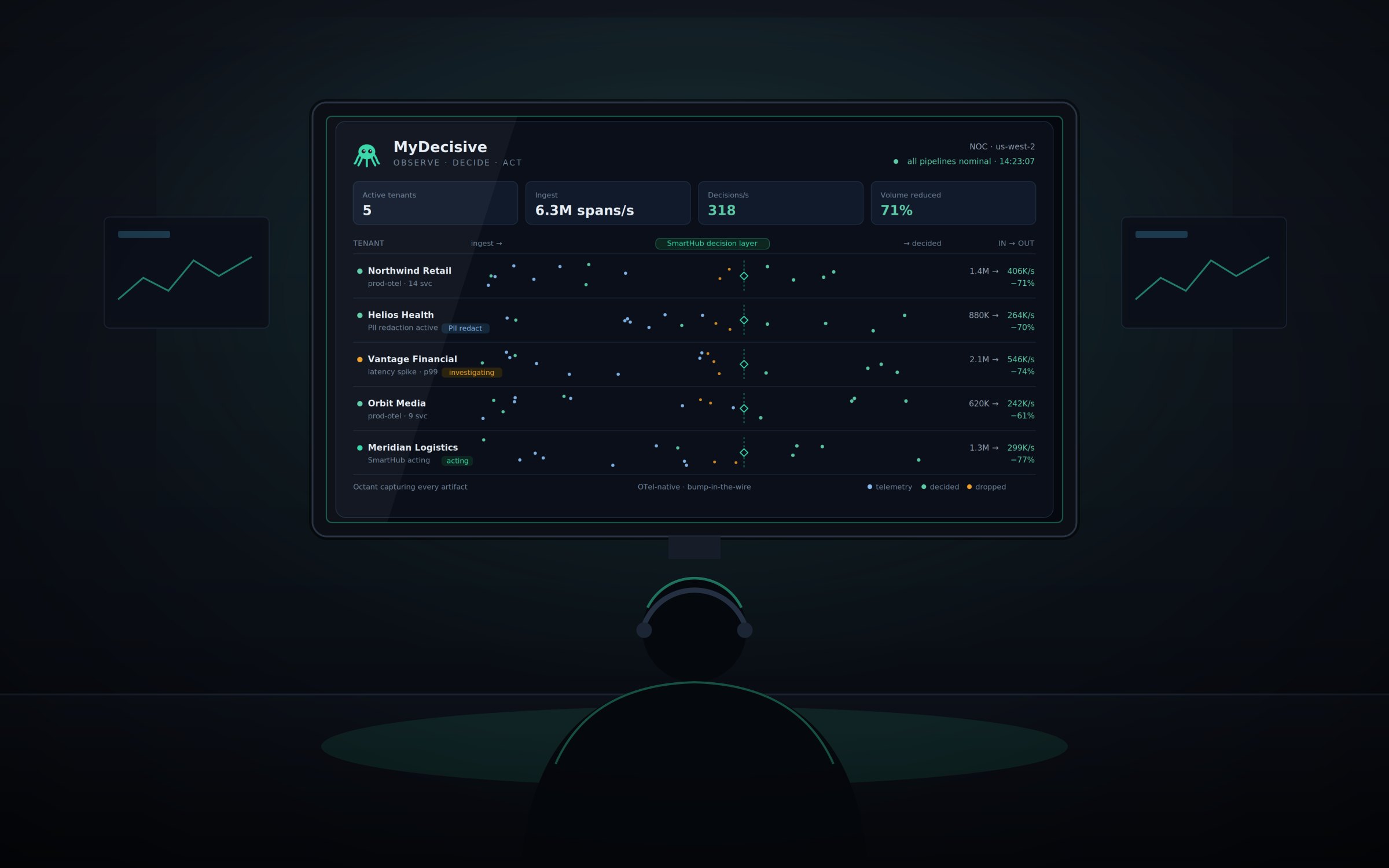
If you have run on-call for a multi-tenant system, the "noisy tenant" is a familiar problem. A single customer floods the system with more connections than it can handle, eating up application resources faster than you can manually intervene. Left unchecked, one tenant's load can trigger a cluster-wide impact — turning a localized issue into a much wider outage.
It's a well-understood failure mode, and community contributor Ali Salehi decided to use his SRE POV to take a run at it. Using the newly released mdai-labs, which leverages OpenTelemetry pipelining, Ali built a dynamic, agentic workflow that both prevents database failovers and reduces observability costs along the way. Here's how it works.
The Problem: Cascading Failures & Wasted Telemetry
Static thresholds fail during sudden spikes. If a tenant pushes heavy database load, generating 500s and 429s, traditional monitoring just alerts you while the database goes down. And if you do manage to rate-limit them, your system starts generating thousands of 429 Too Many Requests traces — so you end up paying steep ingestion fees to store 429 traces that bury the real issues your other tenants are facing. You already know you're rate-limiting, and which tenant is causing it; what you want to know is the impact.
The Solution: Dynamic Mitigation & Telemetry FinOps
Ali (with an assist from Claude) used MyDecisive to wire telemetry signals directly into an active feedback loop, built from a single-paragraph prompt in under ten minutes. Here's the logic he built into the MDAI pipeline:
-
Detect the Spike: MyDecisive monitors the DB error rate across tenants. When errors spike, it isolates the noisy tenant by activating a rate-limit flag in the application via a combination of webhook plus app API call. Rate-limiting is just one option here — because the trigger can fire a generic webhook and API call, you can wire it to whatever mitigation fits your system, whether that's shedding load, scaling a resource, rerouting traffic, or something else.
-
Agentic Rate Limiting: Instead of waking up an engineer, MyDecisive dynamically rate-limits the noisy tenant, throwing 429s and immediately dropping the database load back to healthy levels. Now, MyDecisive starts tracking the frequency of 429s from the noisy tenant and can automatically remove the throttle when the tenant stops firing calls at the system.
-
Smart Trace Sampling: Here is the brilliant FinOps part. The pipeline explicitly drops the trace sampling rate to ~1% for all 429s emitted by the rate-limited tenant, saving massive ingestion costs.
-
Preserve the Signal: Real application errors for the noisy tenant are still tracked, and trace sampling for healthy tenants is temporarily lowered during the incident to reduce noise while the team investigates.
The Code Snippet
Here is an example of what that dynamic, stateful policy looks like inside a MyDecisive pipeline configuration:
processors:
tail_sampling:
decision_wait: 10s
policies:
# 0. THROTTLE-DROP. A noisy-tenant span that was rejected by our own
# rate-limiter (throttled==true). These 429s are MDAI's mitigation
# working as intended — no diagnostic value — so we keep ~1% as a
# sanity sample and drop the other 99%. This policy is FIRST so it
# wins over noisy-tenant-normal (which would otherwise keep 50% of
# them). The 429 *rate* is still fully visible in metrics
# (app_throttled_total / the Action-1 panel); we just stop paying
# to store the redundant per-request traces.
- name: noisy-tenant-throttled-drop
type: and
and:
and_sub_policy:
- name: is-noisy-tenant
type: string_attribute
string_attribute:
values:
- ${env:NOISY_TENANT_LIST:-a^}
key: tenant
enabled_regex_matching: true
- name: is-throttled
type: ottl_condition
ottl_condition:
error_mode: ignore
span:
- 'attributes["throttled"] == true'
- name: keep-1-percent
type: probabilistic
probabilistic:
sampling_percentage: 1
# 1. KEEP EVERYTHING from a noisy tenant that hit a *genuine* DB error (5xx).
# Deliberately does NOT match 429s — those were handled by policy 0
# above. We match the injected-error attribute our /work handler sets,
# OR a Status.ERROR that is not a throttle.
- name: noisy-tenant-errors
type: and
and:
and_sub_policy:
- name: is-noisy-tenant
type: string_attribute
string_attribute:
key: tenant
# When NOISY_TENANT_LIST is unset/empty, expand to "a^" — a regex
# that matches no string. Without this, the empty regex matches
# everything and inverts the policy semantics.
values:
- ${env:NOISY_TENANT_LIST:-a^}
enabled_regex_matching: true
# Genuine DB failures only. We match the injected-error attribute our
# /work handler sets, OR a Status.ERROR that is NOT a throttle (the
# second clause excludes 429 spans, which carry throttled==true).
- name: is-genuine-error
type: ottl_condition
ottl_condition:
error_mode: ignore
span:
- 'attributes["error.injected"] == true'
- 'status.code == STATUS_CODE_ERROR and attributes["throttled"] != true'
# 2. Sample 50% of the noisy tenant's non-error traffic (still want context).
- name: noisy-tenant-normal
type: and
and:
and_sub_policy:
- name: is-noisy-tenant
type: string_attribute
string_attribute:
key: tenant
# When NOISY_TENANT_LIST is unset/empty, expand to "a^" — a regex
# that matches no string. Without this, the empty regex matches
# everything and inverts the policy semantics.
values:
- ${env:NOISY_TENANT_LIST:-a^}
enabled_regex_matching: true
- name: probabilistic
type: probabilistic
probabilistic:
sampling_percentage: 50
# 3. Healthy tenants ride 2%. They were fine before, they're fine now — save the budget.
- name: healthy-tenant-sample
type: and
and:
and_sub_policy:
- name: is-healthy-tenant
type: string_attribute
string_attribute:
key: tenant
values:
- ${env:HEALTHY_TENANT_LIST:-a^}
enabled_regex_matching: true
- name: probabilistic
type: probabilistic
probabilistic:
sampling_percentage: 2
# 4. Default catch-all for spans without a tenant attribute (e.g., infra).
- name: default-sample
type: probabilistic
probabilistic:
sampling_percentage: 10
Full Pull Request can be found here
The Video Demo
Want to see it in action? Watch the 3-minute Loom walkthrough where Salehi spins up the load test, isolates the noisy tenant, and forces the trace drops in real-time.
Why MyDecisive
This is where MyDecisive breaks the cycle. By allowing teams to deploy OpenTelemetry in minutes rather than weeks, MyDecisive drops a stateful, AI-driven proxy directly into your cloud environment. Instead of acting as a dumb pipe that blindly forwards every event to an expensive backend, it novelly intercepts the telemetry stream at the edge. Because it maintains state internally and because it actually understands the context of the incident through its deep understanding of telemetry data and context, Mydecisive instantly throttles the offending tenant while simultaneously filtering out the resulting storm of useless 429 traces. You stop the impact, kill the noise, and only pay to ingest the high-value errors you actually need for debugging and customer management.
Come Build With Us
This is exactly why we open-sourced the MyDecisive platform - to let engineers build the tools that prevent them from being paged, while maintaining reliability.
We are actively looking for more engineers to test the limits of the MyDecisive and MDAI Labs. Whether you want to build intelligent auto-rollbacks, dynamic sampling pipelines, or cost-deflection rules, we want your code.
Star the repo and check out the CONTRIBUTING.md (we just added our CLA!), and take the platform for a spin.
See MyDecisive Solutions in action here.
Find us on GitHub.