If you manage enterprise infrastructure today, you already know the pain of the "observability tax." You scale your systems to meet demand, but the cost of monitoring those systems scales even faster. Suddenly, you aren't just paying to run your applications — you're paying a massive premium just to store the logs that prove they are running.
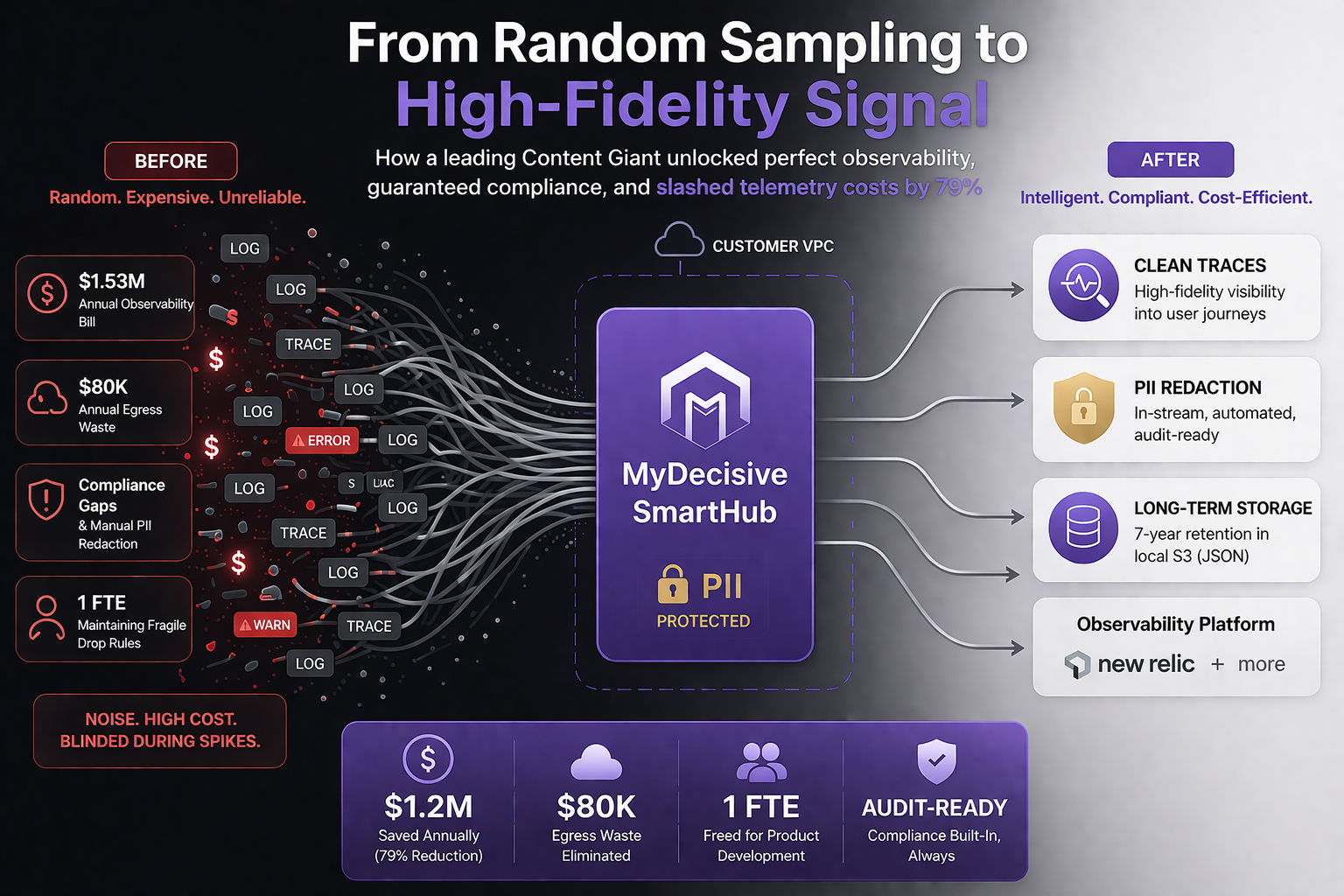
Recently, a global content leader hit their breaking point with this exact problem. Despite user traffic stabilizing post-COVID, their legacy, "send everything and pray" monitoring stack was generating an unsustainable $1.53 million annual observability bill.
Here is the story of how they took control of their telemetry at the edge, killed their vendor overages, and reduced their total observability spend by 79% in just one month.
The Breaking Point: Drowning in Data, Starving for Signal
Desperate to control their runaway New Relic ingestion costs, the platform engineering team attempted a classic DIY fix: they built a homegrown log-filtration script.
If a service crossed a strict 10GB/hour threshold, the script simply muted that service for an hour. This approach proved disastrous. High-volume bursts are exactly when debugging data is most critical. By muting services, the script frequently "orphaned" logs, leaving developers completely blind during high-stakes startup windows and production incidents.
Beyond making debugging a nightmare, this legacy architecture was bleeding resources in three ways:
-
The Cloud Egress Leak: Filtering happened after data left their Virtual Private Cloud (VPC). The company was paying $80,000 annually in AWS data transfer fees just to move telemetry they ultimately planned to drop.
-
The Compliance Trap: Industry regulations required 7-year data retention and strict PII redaction. Fulfilling this required complex AWS Kinesis workarounds and massive manual engineering toil to hand-tag sensitive data.
-
Developer Burnout: The fragile filtration script required a full-time engineer just to maintain it.
The team was stuck. They were paying premium ingestion prices for useless noise, yet losing the critical signals required to actually troubleshoot their systems.
The Fix: Edge-Native Telemetry Control
To break this cycle, the team decided to stop reacting to telemetry volume and start actively orchestrating it. They deployed MyDecisive, shifting the intelligence layer directly to the edge of their network.
By deploying MyDecisive’s SmartHub natively within their own VPC, the team gained an intelligent telemetry pipeline. Using the Octant management plane, they replaced their blunt "on/off" scripts with a highly precise, three-tier strategy for data health:
-
Dynamic Signal Optimization: SmartHub introduced burst-aware filtering. It now preserves 100% of ERROR, WARN, and CRITICAL signals while intelligently sampling healthy "noise" (like standard 200 OK traces). Developers get exactly what they need, exactly when they need it.
-
In-Stream Data Governance: PII redaction is now executed "on the wire." It acts as a set-and-forget feature, entirely removing the manual tagging burden from the engineering team.
-
Zero-Egress Archival: Compliance-mandated data is routed directly to local S3 buckets in structured JSON format. This natively satisfied the 7-year retention requirement and instantly killed the need for expensive secondary firehose pipelines.
With MyDecisive SmartHub, errors are always forwarded, healthy data is sampled, and PII/Compliance needs are handled inline at the edge.
The Impact: High-Fidelity Signal at a Fraction of the Cost
The transition from a metric-heavy monitoring model to a trace-centric observability strategy took just 30 days, and the results were immediate.
Total annual observability spend plummeted from $1.53 million to roughly $300,000 — a 79% reduction. Even further, the $80,000 in network egress waste vanished overnight.
More importantly, engineering found a happy balance. The dedicated "log engineer" was freed up to return to core product development. Developers stopped complaining about missing logs because precision sampling ensured critical startup data was never lost. By separating "insight" (high-value traces) from "storage" (raw logs in S3), the team built a system that satisfied deep-freeze audits without cluttering their active troubleshooting dashboards.
3 Takeaways for Your Own Engineering Team
Reflecting on the transformation, the company's VP of Engineering Operations had advice for organizations facing similar data gravity:
- Separate insight from storage: You need high-fidelity signals for troubleshooting, but you shouldn't pay premium SaaS ingestion prices just to store raw compliance logs.
- Optimize at the edge: Stop paying egress charges to move data you ultimately plan to drop. Process and filter telemetry inside your VPC.
- Automate governance: PII redaction and long-term retention should be inline and automatic, not a manual fire drill that steals engineering capacity.
Download the Case Study here.
Ready to stop paying the observability tax? MyDecisive makes open observability a reality. Wherever your data comes from, wherever it needs to go, MyDecisive delivers the freedom and flexibility to make choices, not compromises.
Get started with 100% Open Source MyDecisive today. See us in action now